В этой статье я постараюсь ответить на следующие вопросы:
Зашел я недавно в Яндекс.Вебмастер, чтобы посмотреть, что делает поисковый робот Яндекса на моем сайте. Как подключить свой сайт к Яндекс.Вебмастер Вы можете посмотреть если перейдете по ссылке. И увидел, что в поиск попадает много ненужных страниц, которые там совершенно не нужны. Казалось бы, что плохого, когда в индексе поисковика много страниц, а плохое есть.
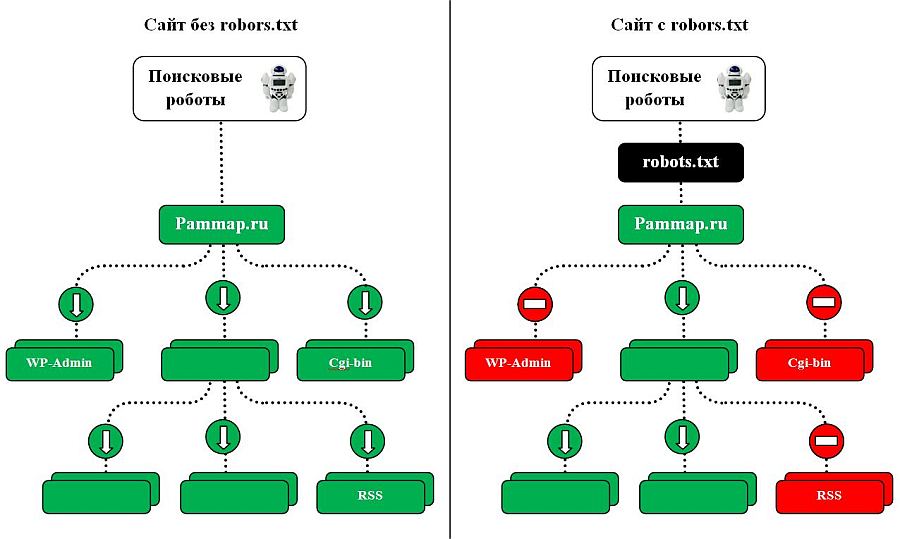
Было решено закрыть доступ для поисковых роботов к некоторым страницам сайта. В этом нам поможет файл robots.txt.
robots.txt – это обычный текстовый файл, в котором прописаны инструкции для поисковых роботов. Первое что делает поисковый робот при попадании на сайт, это ищет файл robots.txt. Если файл robots.txt не найден или он пустой, то поисковый робот будет бродить по всем доступным страницам и каталогам сайта (включая системные каталоги), в попытке проиндексировать содержимое. И не факт, что он проиндексирует нужную Вам страницу, если вообще доберется до нее.
С помощью robots.txt мы можем указать поисковым роботам, на какие страницы можно заходить и как часто, а куда ходить не стоит. Инструкции могут быть указаны, как для всех роботов, так и для каждого робота в отдельности. Страницы, которые закрыты от поисковых роботов, не будут появляться в поисковиках. Если этого файла нет, то его обязательно необходимо создать.
Файл robots.txt должен находиться на сервере, в корне вашего сайта. Файл robots.txt можно посмотреть на любом сайте в Интернет, для этого достаточно после адреса сайта добавить /robots.txt . Для сайта PAMMAP.RU адрес, по которому можно посмотреть robots.txt будет выглядеть так: pammap.ru/robots.txt.
Файл robots.txt , обычно у каждого сайта имеет свои особенности и бездумное копирование чужого файла, может создать проблемы с индексированием вашего сайта поисковыми роботами. Поэтому нужно четко понимать назначение файла robots.txt и назначение инструкций (директив), которые мы будем использовать, при его создании.
Разберем основные инструкции (директивы), которые мы будем использовать при создании файла robots.txt.
User-agent: — указываем имя робота, для которого будут работать все нижеприведенные инструкции. Если инструкции нужно использовать для всех роботов, то в качестве имени используем * (звездочку)
Имена самых популярных поисковиков Рунета это Googlebot (для Google) и Yandex (для Яндекса). Имена остальных поисковиков, если интересно, можно найти на просторах Интернет, но создавать для них отдельные правила, мне кажется, нет необходимости.
Disallow – запрещает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Allow – разрешает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Sitemap: — можно использовать для указания пути к файлу с описанием структуры вашего сайта (карты сайта). Она нужна для ускорения и улучшения индексации сайта поисковыми роботами.
Host: — Если у вашего сайта есть зеркала (копии сайта на другом домене). Например pammap.ru и www.pammap.ru. С помощью файла Host можно указать главное зеркало сайта. В поиске будет участвовать только главное зеркало.
Также можно использовать спецсимволы. * # и $
*(звездочка) – обозначает любую последовательность символов.
$(знак доллара) – По умолчанию в конце каждого правила предполагается наличие *(звездочка) чтобы отменить симовол *(звездочка) можно использовать символ $(знак доллара).
#(знак решетки) – можно использовать для комментариев в файле robots.txt
Подробнее с этими директивами, а также несколькими дополнительными, можно ознакомиться на сайте Яндекса.
Теперь приступим к созданию файла robots.txt. Так как наш блог работает на WordPress, то разберем процесс создания robots.txt для WordPress более подробно.
Вначале нужно определиться, что мы хотим разрешить поисковым роботам, а что запретить. Я для себя решил оставить только самое необходимое, это записи, страницы и разделы. Все остальное будем закрывать.
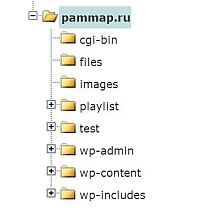
Какие папки есть в WordPress и что необходимо закрыть мы можем увидеть, если посмотрим в директорию нашего сайта. Я сделал это через панель управления хостингом на сайте reg.ru, и увидел следующую картину.
/cgi-bin (каталог скриптов на сервере – в поиске он нам не нужен.)
/files (каталог с файлами для загрузки. Здесь, например, лежит архивный файл с таблицей Excel для подсчета прибыли, о которой я писал в статье «Как посчитать прибыль от инвестиций в ПАММ счета«. В поиске этот каталог нам не нужен.)
/playlist(этот каталог я сделал для себя, для плейлистов на IPTV – в поиске не нужен.)
/test (этот каталог я создал для экспериментов, в поиске этот каталог не нужен)
/wp-admin/ (админка WordPress, в поиске она нам не нужна)
/wp-includes/ (системная папка от WordPress, в поиске она нам не нужна)
/wp-content/ (из этого каталога нам нужен только /wp-content/uploads/ в этом каталоге находятся картинки с сайта, поэтому каталог /wp-content/ мы запретим, а каталог с картинками разрешим отдельной инструкцией.)
Также нам не нужны в поиске следующие адреса:
Архивы – адреса вида //pammap.ru/2013/ и похожие.
Метки — в адресе меток содержится /tag/
RSS фиды — в адресе всех фидов есть /feed
Записи автора — в адресе есть /author/ (тем более, что автор всего один)
На всякий случай закрою адреса с PHP на конце так, как многие страницы доступны, как с PHP на конце, так и без. Это, как мне кажется, позволит избежать дублирования страниц в поиске.
Также закрою адреса с /GOTO/ я их использую для перехода по внешним ссылкам, в поиске им точно делать нечего.
И напоследок, уберем из поиска короткие адреса, вида //pammap.ru/?p=209 и поиск по сайту //pammap.ru/?s=, а также комментарии (адреса в которых содержится /?replytocom= )
А вот что у нас должно остаться:
/images (в этот каталог я закидываю некоторые картинки, пускай этот каталог роботы посещают)
/wp-content/uploads/ — содержит картинки от сайта.
Статьи, страницы и разделы, которые содержат понятные, читаемые адреса.
Например: //pammap.ru/portfel/ или Мои инвестиции
А теперь придумаем инструкции для robots.txt. Вот, что у меня получилось:
#Указываем, что эти инструкции будут выполнять все роботы
User-agent: *
#Разрешаем роботам бродить по каталогу uploads.
Allow: /wp-content/uploads/
#Запрещаем папку со скриптами
Disallow: /cgi-bin/
#Запрещаем папку files
Disallow: /files/
#Запрещаем папку playlist
Disallow: /playlist/
#Запрещаем папку test
Disallow: /test/
#Запрещаем все, что начинается с /wp- , это позволит закрыть сразу несколько папок, имена которых начинаются с /wp- , эта команда вполне может помешать индексации страниц или записей которые начинаются с /wp-, но давать таких имен я не планирую.
Disallow: /wp-*
#Запрещаем адреса, в которых содержится /?p= и /?s=. Это короткие ссылки и поиск.
Disallow: /?p=
Disallow: /?s=
#Запрещаем все архивы до 2099 года.
Disallow: /20
#Запрещаем адреса с расширением PHP на конце.
Disallow: /*.php
#Запрещаем адреса, которые содержат /goto/. Можно было не прописывать, но на всякий случай вставлю.
Disallow: /goto/
#Запрещаем адреса меток
Disallow: /tag/
#Запрещаем статьи по автору.
Disallow: /author/
#Запрещаем все фиды.
Disallow: */feed
#Запрещаем индексацию комментариев.
Disallow: /?replytocom=
#Ну и напоследок прописываем путь к нашей карте сайта.
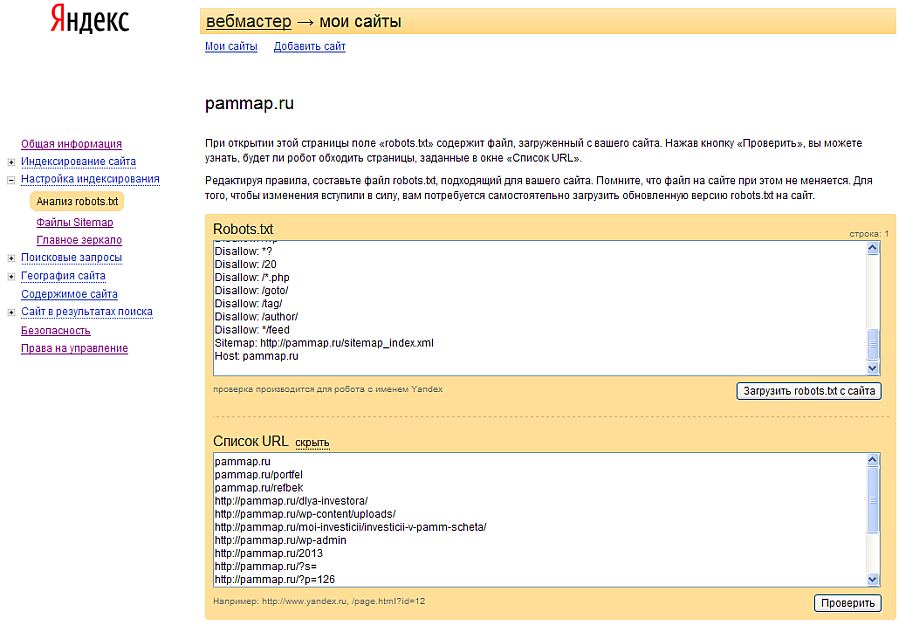
Sitemap: //pammap.ru/sitemap_index.xml
Написать файл robots.txt для WordPress можно с помощью обычного блокнота. Создадим файл и запишем в него следующие строки.
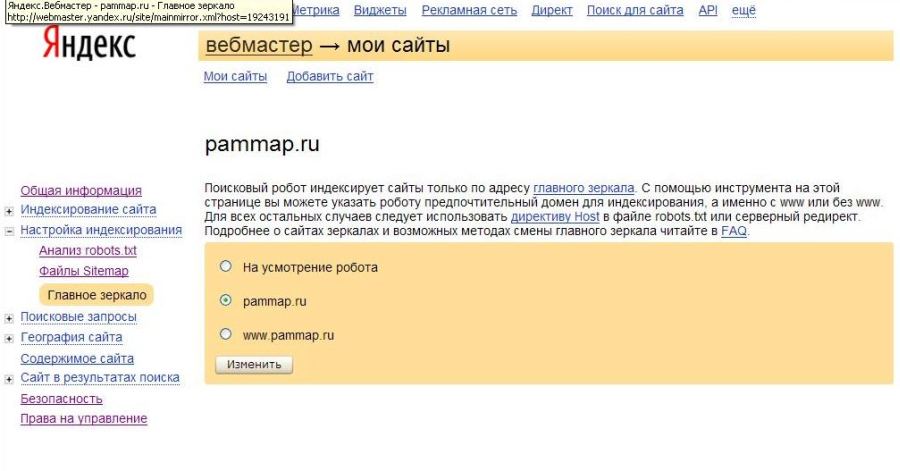
Вначале я планировал сделать один общий блок правил для всех роботов, но Яндекс работать с общим блоком отказался. Пришлось сделать для Яндекса отдельный блок правил. Для этого просто скопировал общие правила, изменил имя робота и указал роботу главное зеркало сайта, с помощью директивы Host.
Указать главное зеркало сайта можно также через Яндекс.Вебмастер, в разделе «Главное зеркало»
Теперь, когда файл robots.txt для WordPress создан, нам его необходимо загрузить на сервер, в корневой каталог нашего сайта. Это можно сделать любым удобным для Вас способом.
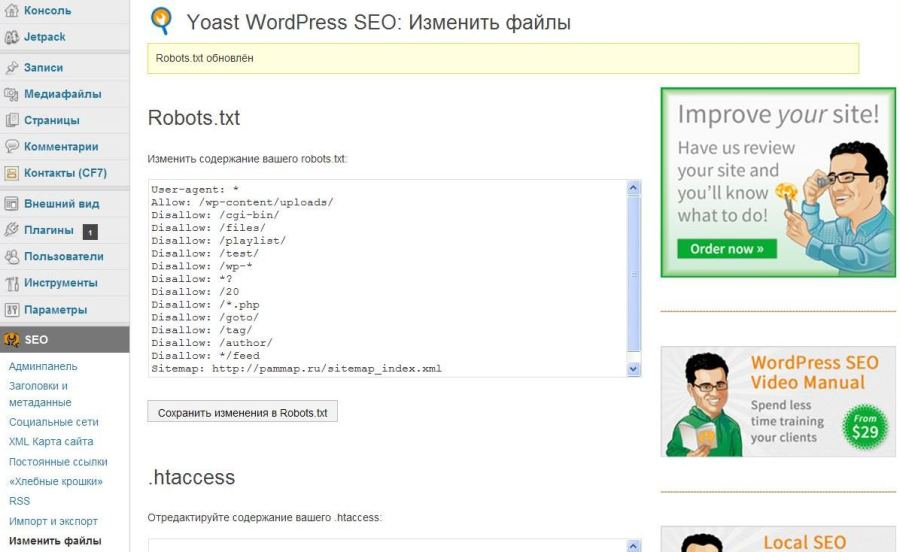
Также для создания и редактирования robots.txt можно воспользоваться плагином WordPress SEO. Подробнее об этом полезном плагине я напишу позже. В этом случае файл robots.txt на рабочем столе можно не создавать, а просто вставить код файла robots.txt в соответствующий раздел плагина.
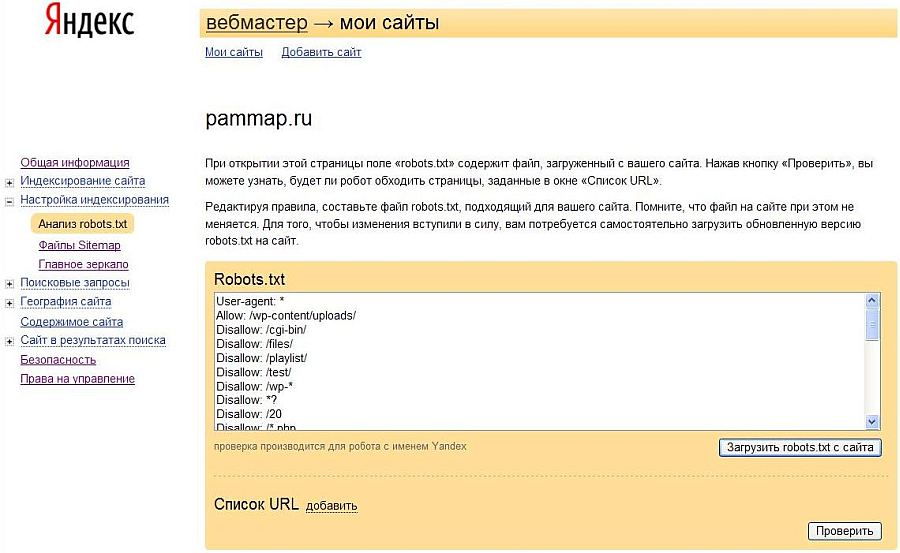
Теперь, когда мы создали файл robots.txt, его нужно проверить. Для этого заходим в панель управления Яндекс.Вебмастер. Далее заходим в раздел “Настройка индексирования”, а далее “анализ robots.txt” . Здесь нажимаем кнопку «Загрузить robots.txt с сайта», после этого в соответствующем окне должно появиться содержимое вашего robots.txt.
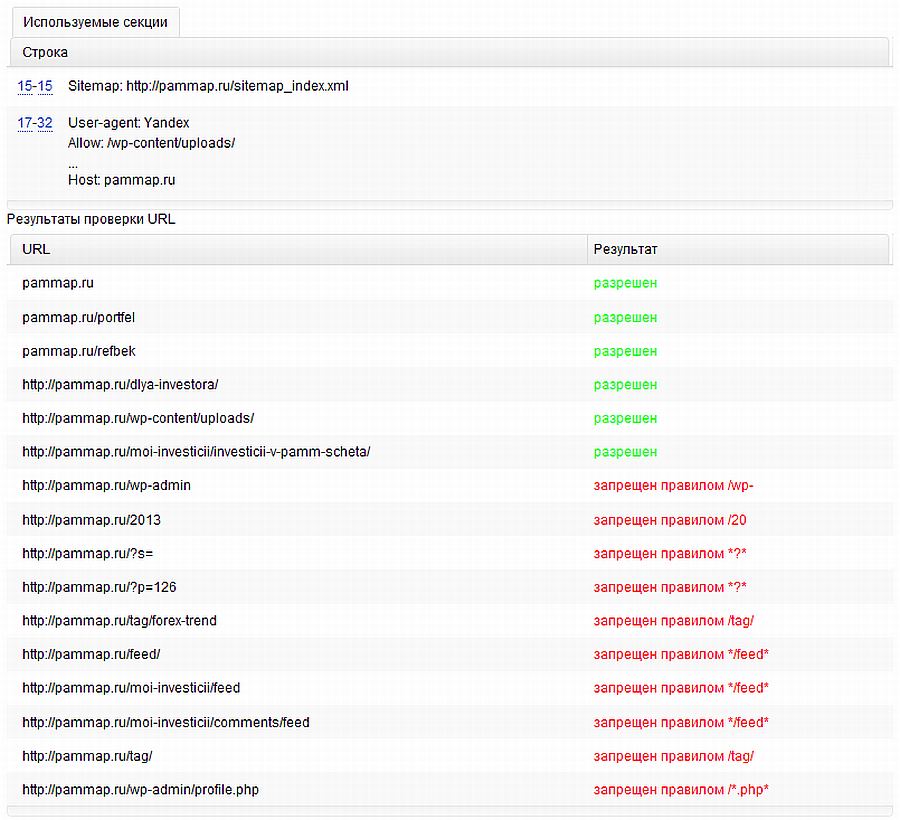
Затем нажимаем «добавить» и в появившемся окне вводим различные url с вашего сайта, которые вы хотите проверить. Я ввел несколько адресов, которые должны быть запрещены и несколько адресов, которые должны быть разрешены.
Нажимаем кнопку «Проверить», после этого Яндекс выдаст нам результаты проверки файла robots.txt. Как видим, наш файл проверку удачно прошел. То, что должно быть запрещено для поисковых роботов, у нас запрещено. То, что должно быть разрешено, у нас разрешено.
Такую же проверку можно провести для робота Google, через GoogleWebmaster, но она не сильно отличается от проверки через Яндекс, поэтому я ее описывать не буду.
Вот и все. Мы создали robots.txt для WordPress и он отлично работает. Остается только иногда поглядывать за поведением поисковых роботов на нашем сайте. Чтобы вовремя заметить ошибку и в случае необходимости внести изменения в файл robots.txt. Страницы которые были исключены из индекса и причину исключения можно посмотреть в соответствующем разделе Яндекс.ВебМастер (или GoogleWebmaster).
Актуальную версию моего файла robots.txt всегда можно посмотреть по ссылке pammap.ru/robots.txt
Удачных Инвестиций и успехов во всех ваших делах.
С уважением Сергей,
Автор блога Pammap.ru
Впереди лето - сезон, на который приходится большая часть дат закрытия реестров по выплате дивидендов.…
Продолжаю рассматривать производные индикаторы на основе базовых мультипликаторов оценки финансовых результатов компании. Сегодня на очереди…
Мультипликатор EV / EBITDA отчасти является аналогией другого мультипликатора Р/Е, так как используется для той…
Что такое Enterprise Value (EV)? Значение Enterprise Value, или EV для краткости, является мерой общей…
Чистый долг (Net Debt) применяется в более детализированных (объективных) мультипликаторах - EV (Enterprise Value), Net…
Рыночная капитализация - оценочный индикатор, позволяющий проанализировать общее отношение инвесторов к той или иной компании.…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
View Comments
Я вот о их пор не настроил роботс на своем блоге и у меня в выдаче куча мусора. стоит ли теперь этим заниматься или уже поздно?
Александр, конечно нужно. Ведь robots.txt делается для роботов, которые заносят в индекс страницы вашего блога, как только вы настроите правильно robots.txt, роботы уже не будут их индексировать и они автоматически выпадут из выдачи.
Никогда не поздно. После настройки робота лишнее выпадет из выдачи.